
Research challenges were the topic of this recent post. Today, we want to give you some insight into how you can address the challenge of identifying fund manager gender using demographics information!
The gender challenge
The basic take-away of our last post: Identifying a fund manager’s gender based on first names reduced the sample by 97.5%. This reduction was unacceptable: we would have been forced to base our analysis on only 23 female managers. So we repeated steps 1 to 5 from the post, which gave us 11,114 different first name/last name combinations. We then checked for spelling errors (e.g., Adam Cary Sm!th, Jr. is probably Adam Cary Smith, Jr.). Such errors are surprisingly frequent, and we reduced the 11,114 combinations to 7,720 combinations.
A new identification strategy – using demographics!
We next fine-tuned our identification strategy. The basic idea is to calculate the probability that a manager with a certain name has a certain gender. In detail, we proceeded as follows:
- We downloaded a new version of the SSA list, containing how often a name is given to a baby in a given calender year. The time series we consider is from 1920 to 2015 – it is plausible that managers who are working in 1992 are rarely older than 70.
- We then calculated the probability that a certain name (e.g., Kim) refers to a male manager by computing the total number of male babies with this name, relative to all babies with this name:
 . So, the probability that a baby named KIM is 37.5% in this example
. So, the probability that a baby named KIM is 37.5% in this example - We next must decide on a cutoff probability where we feel sufficiently confident that a manager is male. We settled on a 95% probability.
The outcome
So, what does the sample of matched first names with cutoff of 95% look like?
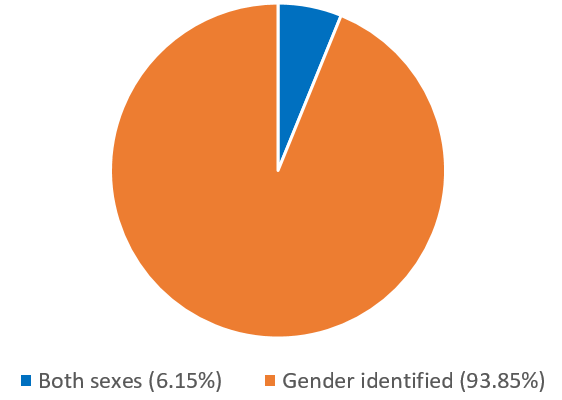
Figure 1: Fund manager gender by name based on frequencies (Source: CRSP database, SSA, own calculation)
Figure 1 shows the dramatic improvement: Out of the 7,720 names, we can now identify 7,245 (94%) as either female or male!
And Figure 2 shows that our assumption of a 90% male ratio in the previous post was realistic.
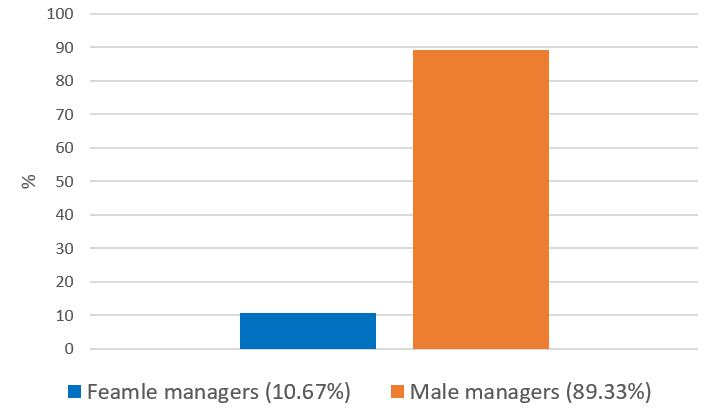
Figure 2: Fund manager gender of identified managers (Source: CRSP database, SSA, own calculation).
Out of the 7,245 managers, 6,472 (89%) are male, and 773 are female. So, we now have a large and reliable sample.
Constructing a matched sample
In some applications, it may be preferrable to use only a part of this large sample. One example is the fund objective. We eventually want to compare funds managed by male and female managers. But if the fund objectives differ (such as a growth fund and a value fund), we could easily mis-attribute performance differences to gender – when they are really due to the different objectives. So, if we drop all funds which do not clearly state their objective, our sample now only encompasses 2,973 managers – and 76 of them could be male or female with the 95% cutoff. We use web searches to manually collect information on these managers, and Figure 3 shows the distribution of the final sub-sample.
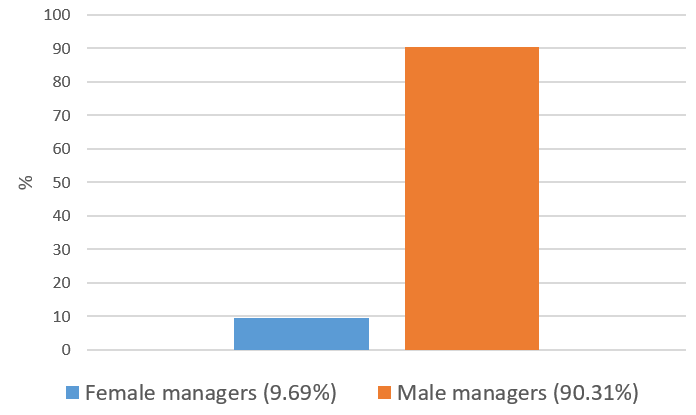
Figure 3: Fund manager gender of final sample (Source: CRSP, SSA, own calculation).
In summary, we now have a sample with roughly 10% female managers (288) and 90% male managers (2,685). Identifying fund manager gender using demographics information from the US Social Security Administration website helped us to obtain a representative sample!
You may also like